Python 爬取有道翻译
Attention: Python3 将urlib2 urlib3 结合为urlib
基本原理
通过给网页提供一个数据,然后获取其反馈
使用到的模块
- urllib.request: 访问网站,提出请求,获取反馈
- urllib.parse: 格式化请求数据
- json: 格式化反馈信息,使其格式化为字典
新版有道翻译爬取实现比较复杂 这里是对老的版本的爬取
实现过程及代码
分步解释
1.
获取处理翻译信息的网页(这里采用的是谷歌浏览器)
打开有道翻译网页 进入开发者模式
选择Network 
然后在左边的输入框随便输入一个单词 会发现多了很多文件 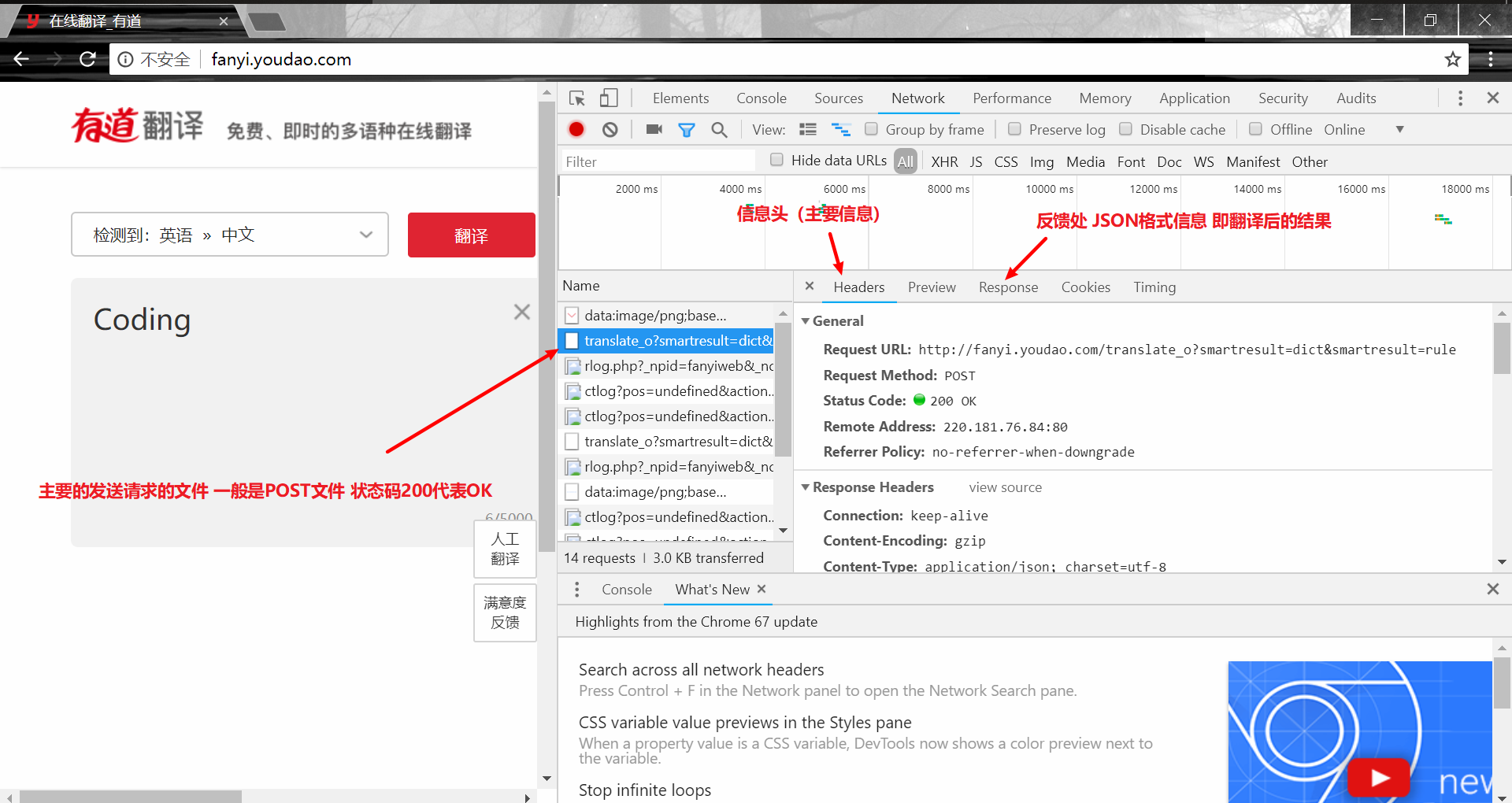 Headers 里面就是我们需要发送给他的信息
Headers 里面就是我们需要发送给他的信息
其中 Request Url 就是真正处理翻译的网页
由于我们采用旧版所以将url里的 "translate_o" 改为
"translate"
1
2# 真正翻译的网址 Request Url
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
2. 发送信息包 如下 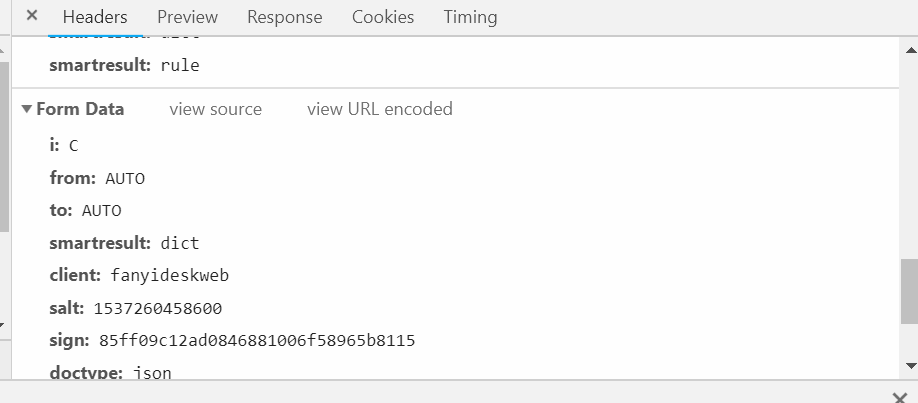 将其包装成字典 并且格式化为网页可以识别的格式
将其包装成字典 并且格式化为网页可以识别的格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 新建列表 模拟传入数据
data = {}
data['i'] = String
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_REALTIME'
data['typoResult'] = 'false'
#该变格式
data = urllib.parse.urlencode(data).encode('utf-8')
3. 获取反馈并处理
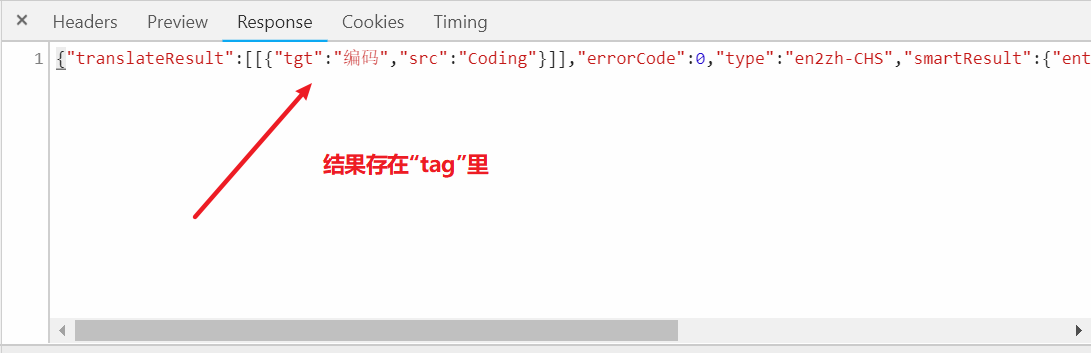
1
2
3
4response = urllib.request.urlopen(url, data) # 得到回复
html = response.read().decode('utf-8') # 重新编码
result = json.loads(html) # json 字典化
# return result["translateResult"][0][0]["tgt"] 返回结果
全部代码如下
1 | ''' |